Proxmox HA Storage: Ceph vs Gluster
When I set up my Proxmox cluster in my homelab I decided to go with Ceph as a storage option.
Ceph is greatly integrated within the Proxmox UI and seems to be a very reliable choice.
However, I started wondering about the performance. I have all flash, I use NVMe for WAL, but the machines on Proxmox just feel slow here and there. I started investigating and read some times, that GlusterFS might be a better choice for 3-node clusters while Ceph will work better on larger clusters. Also I read that Ceph performs really bad on consumer SSDs because it is enforcing cache flush to disk on every write and that’s only fast with Power-Loss-Protection (PLP), which is an Enterprise SSD feature (write and flush is acknowledged as soon as write hits the cache as it’s PLP protected).
Having no enterprise SSDs at hand I started testing GlusterFS on the remaining space of the WAL NVMes (separate LVM volumes) and found that the performance was much better for most workloads than Ceph was. But it was NVMe vs SATA-SSD, so not quite fair but I am interested now.
I bought three refurbished Intel DC S4600 480GB SATA Enterprise SSDs with PLP to give it a real test. I put LVM on the disks and created 100G volumes for each Ceph OSDs, a replicated GlusterFS and a dispersed GlusterFS (Raid 5-like).
I always tested from the same WS2019 VM with CrystalDiskMark.
References
First reference speed is a native LVM on a single node and single Intel SSD DC S4600 2.5″ 480GB SATA 6Gb/s. The tech spec promises 500MB/s read, 480MB/s write at 72k/60k IOPs and the results show that’s real:
The second reference value is a result from my current Ceph layout: 3 Nodes with each 1x 1TB NVMe WAL and 2x 4TB Consumer SATA SSD with a replicated rule of size 2.
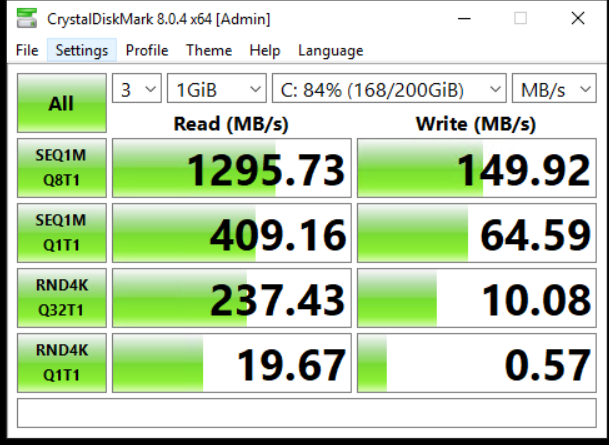
While the read values look quite good (1295MB/s sequential read is the 10GB Ethernet limit), the write values show why Ceph feels so slow. The values are so far off a single native SSD. Especially single threaded 4k random write is 100 times slower on Ceph than on a single SSD.
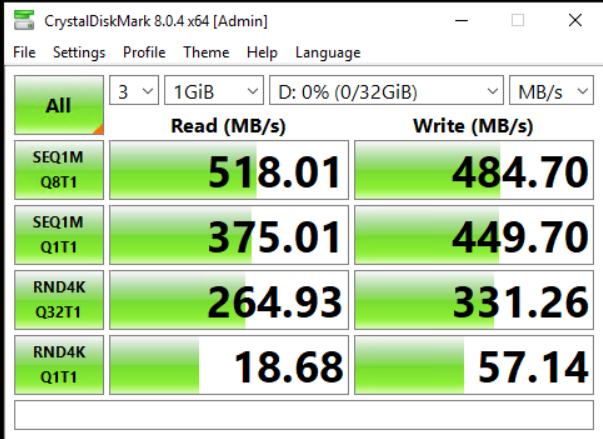
Replicated Ceph
I created a new disk type, a new crush rule selecting these and a new pool based on this replicated rule.
The results show basically the same in read as the consumer Ceph pool but a a 2.5x-8x performance increase in writes. Definitely something! But still far off a single disk.
Replicated GlusterFS
The replicated GlusterFS runs one copy and one arbiter (quorum).
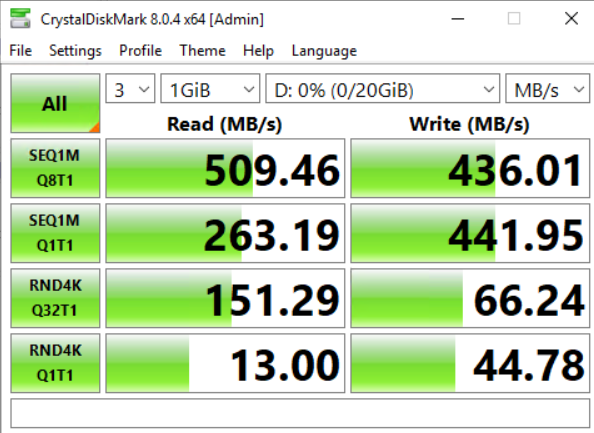
I expected reads to be served from two nodes and seeing higher values as from a single SSD, but as you can see this isn’t the case. Writes are expected to be slower than on a single disk (as there is replication involved), but I was super happy to see that most write tests outperformed Ceph at this time (10x for single-threaded random writes!). Ceph does perform better with parallel write requests though, but still Gluster is better than Ceph on consumer SSDs.
I disabled one of the Gluster daemons to test the Gluster performance in a degraded state but did not see much difference.
Dispersed GlusterFS
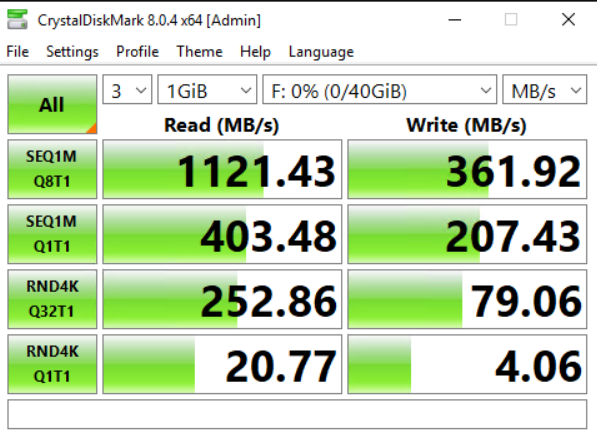
Now let’s look on the dispersed deployment of GlusterFS. It is the most tickling for me, as it would allow me to increase my usable storage from 50% (1:1 copy on Ceph today) to 66% (2+1 redundancy).
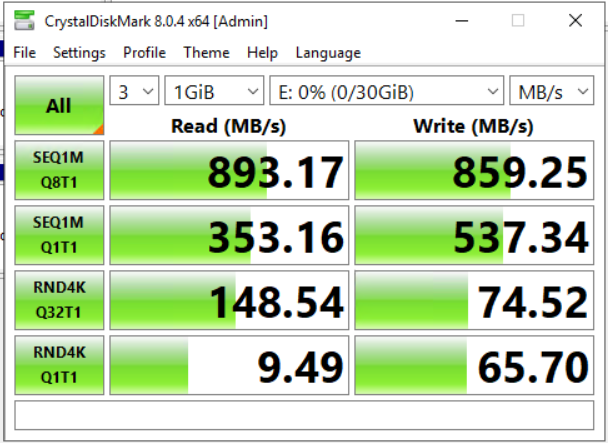
Again the read values are overall not as good as with Ceph, but you can see that sequential workloads are now served by two hosts. Random reads are worse though.
Writes on the other hand do perform great. Even here we can see 2 SSDs writing on the sequential part and random values went up from the replicated deployment, too.
Summary
Looking at these results I am very interested in a dispersed GlusterFS deployment. I recognized the advantage of Enterprise SSDs vs consumer SSDs for Ceph (up to 8x write performance), but the overall performance of Gluster is much better (on writes).
Putting my current Ceph deployment (Consumer SSDs) vs GlusterFS results in the following table:
| Test | Ceph Read (MB/s) | Gluster Read (MB/s) | Diff | Ceph Write (MB/s) | Gluster Write (MB/s) | Diff |
|---|---|---|---|---|---|---|
| SEQ1M Q8T1 | 1296 | 893 | -31% | 150 | 859 | +473% |
| SEQ1M Q1T1 | 409 | 353 | -14% | 65 | 537 | +726% |
| RND4K Q32T1 | 237 | 149 | -37% | 10 | 75 | +650% |
| RND4K Q1T1 | 20 | 10 | -50% | 1 | 66 | +6500% |
Yes, reads are all slower. Up to 50% slower. That sounds a lot, but when you look on the increases in writes which are up to 6500% (actually without rounding that would be even 115x !) better in performance. The gain is at least 10x the loss, so that’s looking okay for me to go down that route (for now).
The next thing on my table is to remove some of the 4TB consumer SSDs from Ceph and give them to Gluster and retest performance on the consumer SSDs before finally deciding which way to go … stay tuned.