Homelab Revamp 2022 – Part 4 – Build, Configure, Learn
So I am running the 2-node VSAN cluster for about 3 months now. Time to wrap up what I learned building, configuring and running it.
Build & Migration
Not much to say here. Building the PCs was an easy task, migrating all the data took some time of course but worked good. Though during the migratin process one of my 4TB SSDs died and the RMA process took quite some time. Still the cluster was already running, but of course with less capacity.
I learned that any change you do to disk groups is forcing full resyncs – that was about 8TB cache writes in only 103h of operation which of course was quite intense for the first days on the TBW.
Migrating the VMs wasn’t that easy because I couldn’t use vMotion because of the different CPU types (I used Intel ones before). When trying to move the VCSA I learned about the importance of having ephemeral networks on your Distributed vSwitches – these will only assign a port on the vSwitch on startup, so you can configure them without vCenter (e.g. for the VCSA when you want to change the port on the ESXi).
Issues
I encountered some other issues during the first days/migration.
- Sudden HA cluster failovers
Due to my network setup I encountered some HA cluster failovers, because the nodes thought they were isolated. I found the solution in the VMware KB1002117: Setting Multiple Isolation Response Addresses for Vsphere High Availability and configured the layer 2 reachable switch IP. - Sudden system reboots
From time to time each of the nodes just rebooted. This happened during the backup high-load phases in the night. vSphere HA kicked in, restarted the VMs, and the node came back some time later. Out of missing monitoring on the hardware and actual monitors connected I wasn’t able to make out the source of this.
I thought the systems might get too warm under load, so I added another system fan (5 EUR each) to the each and the situation improved.
Unfortunately it is not gone, yet. Lately the system ran about a month without issues before the reboot happened again.
I configured remote syslog but didn’t find the source of the issue in the logs. I only noticed the reboot after 3 days though … should improve my monitoring here… - Running nested ESXi needs tweaks
For my labs I am running nested ESXi. Thanks to William Lam’s blog I now know that for the VSAN case I have to enable a setting toFakeSCSIReservations. - High pNic error rate
I got warning messages from time to time about high pNic error rates on my 10G connections. VMware KB50121760 – Troubleshooting network receive traffic faults and other NIC errors in ESXi says I should contact my hardware vendor – well this is not possible for the self-build world, so I just ran the workaround they explained and increased the RX buffer size (to4096helped a lot for my systems).
Plan vs Reality
So time to check if I met my plan (Homelab Revamp 2022 – Part 2 – The Plan) and solved some of my issues.
VMware VSAN
Over all I am really happy with the VSAN. It provides me the shared storage I didn’t have before. I’d love to use VSAN as a remote datastore, too, but this is only possible with a normal VSAN cluster, not in the 2-node version.
Even though I am not using HCL hardware everything worked out of the box and you can disable the annoying no-HCL alarms in VSAN health.
Migration is a process where you write lots and lots of data, and maybe two or three times until everything is setup in a working condition with all the devices.
My current capacity usage is about 61% and I enabled compression to save about 2.18TB on storage. I’ve chosen not to enable deduplication, because I assume this would eat up lots of memory and performance for my small system.
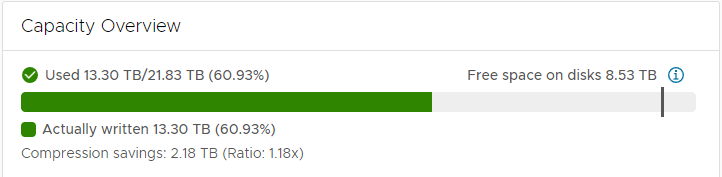
A 24h performance view shows that my usage isn’t very high normally. I do see some spikes for read latencies in the graphs, but I didn’t feel them using any of the VMs. VSAN feels really speedy compared to my previous RAID5 setup.
You can see the high load during my backup window. Throughput speeds stop at SATA level on peaks.
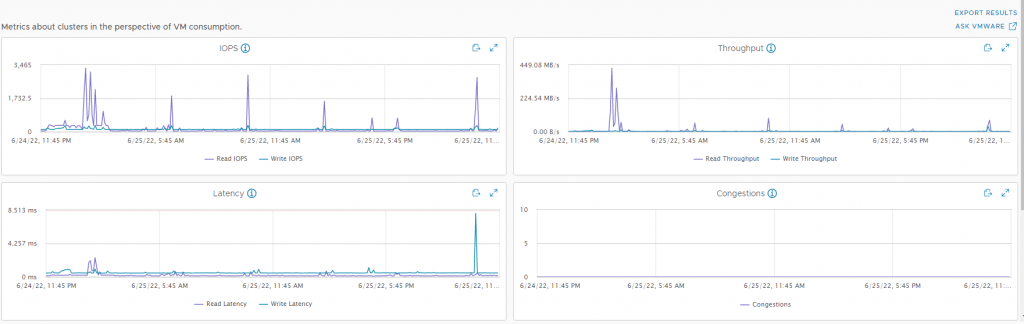
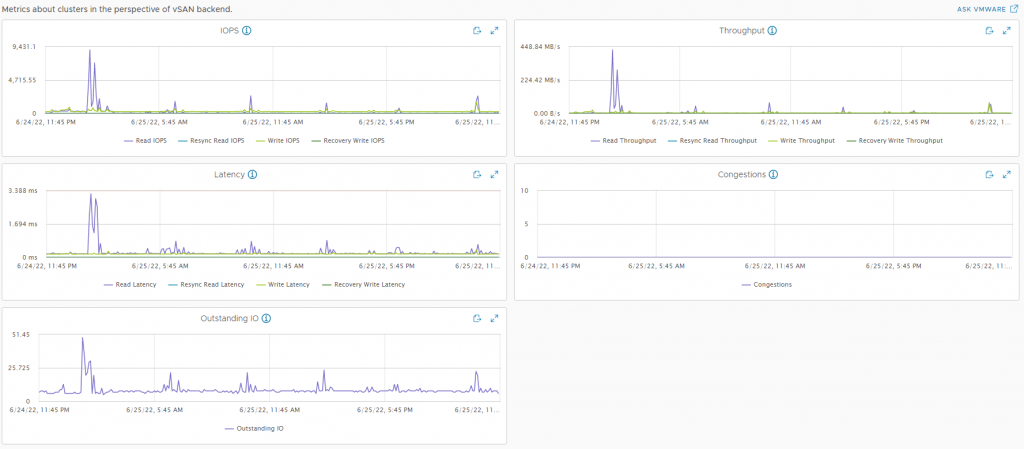
What really works great is when I need to update one of the hosts. Enable maintenance mode and the VMs are quickly moved within the VSAN cluster. When I run all of my VMs I get issues with low memory though, so I might think about adding another node soon.
Consumer Hardware, Availability and power consumption
When I encountered the reboot issue I somewhat thought consumer hardware might have been the wrong choice, but when the situation improved this feeling went away. Even though I still don’t know the root cause and still get reboots I am now happy with my choice.
The reboot-thingy of course affects availability, at least a little bit. As the system recovers itself and vSphere HA kicks in and this happens during the night I hardly notice the reboots.
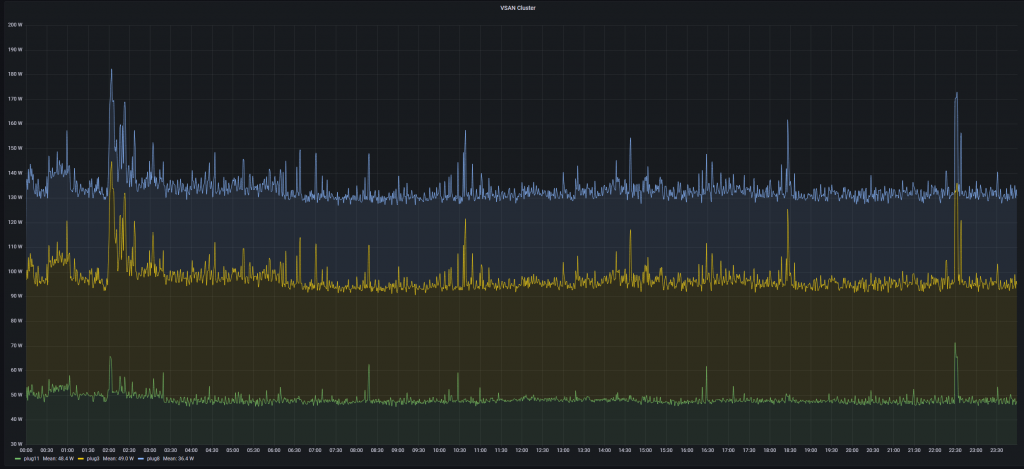
The whole cluster, that means the 2 VSAN nodes + the old ESPRIMO system on which I run the VSAN witness consume less than 140W during normal operations. Peaks in the backup window go up to about 180W. And about 40W of this just comes from the ESPRIMO system with the witness. I can almost run another full VSAN node with this power consumption (which I will at some point).
The 140W is the same my production system used before, but that was a single system, so I won something here. Also I did decomission my lab system and run it also on the cluster.
I track the power usage with Shelly Plug S on each system and a Grafana dashboard (cumulative view of the single plugs):
The performance of the systems is good, I don’t have any issues with CPU power. I could use more memory though, the 2x 128GB are my limiting factor at the moment, when I use my labs. Also here another node would help – also for any maintenance or HA situation, where everything needs to fit into a single node with 128GB today. Alone my 16 production VMs fills this today:
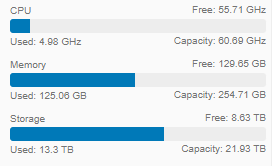
Manual efforts went down a lot. I just need to run Lifecycle Manager update process and everything works on it’s own. I start VMs and DRS thinks about where to start them or where to move them.
Summary
So overall I think of this as a successful project and migration. I am happy with the current state but I plan an update with another node in the near future to get even more out of it.
I’ll write posts from time to time about learnings from the cluster, improvements I built in or whatever I am doing otherwise. Thanks for reading and I hope you found it useful.